TSConf 2019 — TypeScript at the Cutting Edge
Last October I had the chance to speak at TSConf 2019, and share some of our experiences at Cydar using TypeScript in a fairly unusual context. Below is written version of the talk, edited a little to make it read better. You can see a video of the talk itself, along with the other talks at the conference, on the conference website.

First off, a bit about the company. Cydar Medical is an early-stage software company based in the UK. In 2012, Tom Carrell, a vascular surgeon at St Thomas’s hospital in London, was encountering particular kinds of problems in his clinical practice. He asked around and eventually found Graeme Penney, an imaging scientist at KCL. They established the company to see if the technology was viable, figured out it was, got it to the stage where it was working. The next step was to turn it into a product to deliver to clinicians, and that’s where I joined the company in 2014.
The product is Cydar EV (Endovasuclar - I’ll explain that in a moment):

Here it is in action:
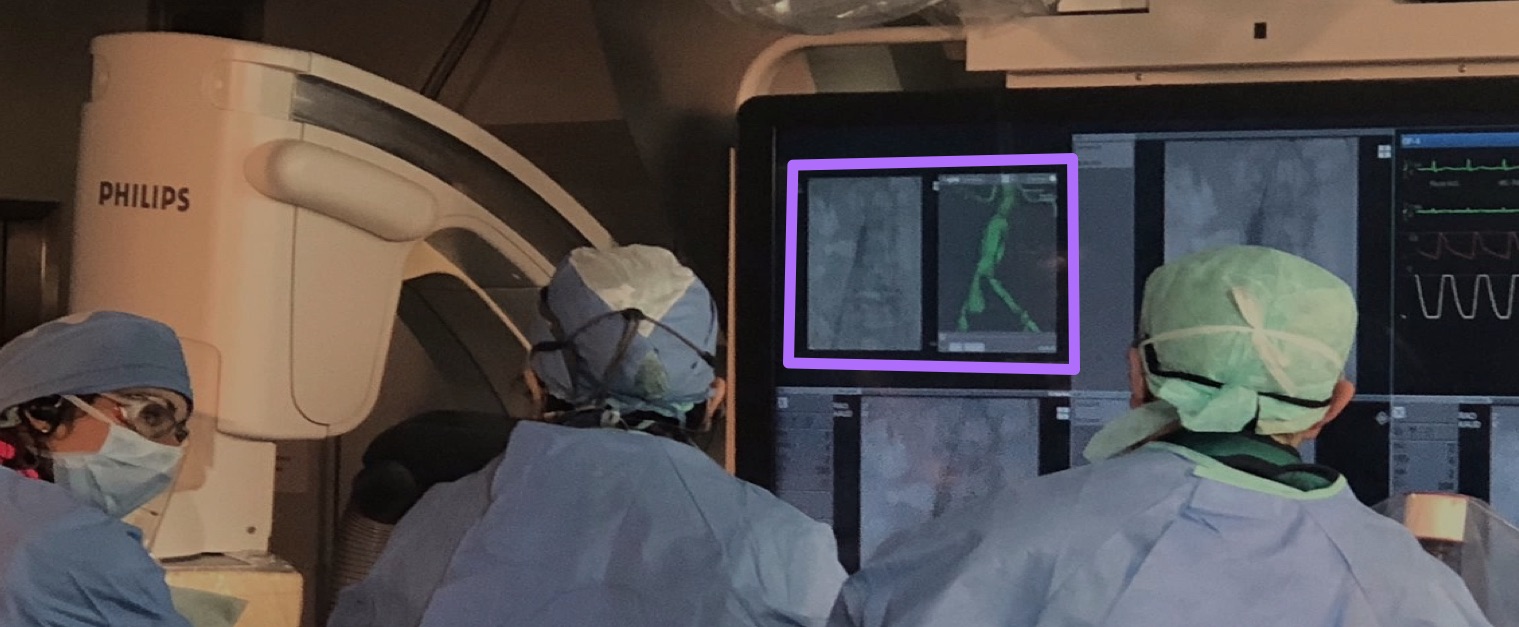
That’s Cydar EV in action on an actual case. It’s CE marked and FDA cleared, and it’s in clinical use in sites in the UK, US and across continental Europe.
I’m afraid that, to explain what you’re looking at there, I’m going to have to take a slight diversion into surgery. One of the key diseases we support the treatment of is abdominal aortic aneurysms:
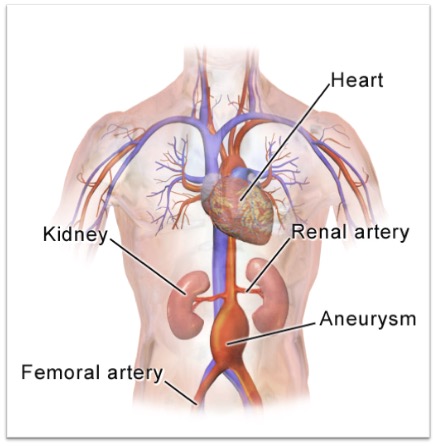
The aorta is the main blood vessel coming from the heart that pumps oxygenated blood through the body, and an aneurysm is where the wall of that vessel weakens, causing it to swell, and if left untreated it can burst. In the case of an aortic aneurysm, that’s often fatal, so you don’t want to let it get to that stage.
The treatment is conceptually pretty simple. You get a cloth tube (a graft), and place it across the diseased part of the vessel. The blood then flows through that tube instead of the aneurysm.This takes pressure off the ansuerysm, which stops expanding and can start to heal. The question is, how do you get that graft in there?
One option is open surgery — the clinician cuts the patient open, and sews in the graft directly. This is effective, but it’s a major procedure, with a very long recovery time.
A very attractive alternative is endovascular surgery, which looks like this1:
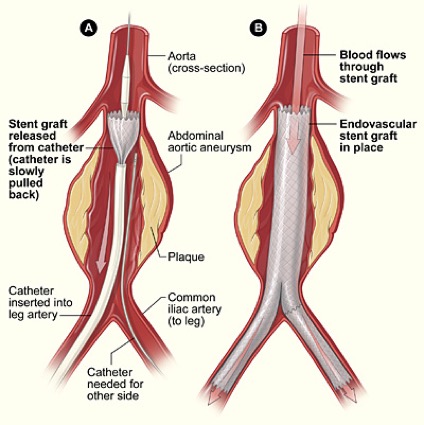
For this, you augment the graft with a springy metal frame – a stent — to produce a stent graft. You crunch it down, and put it inside a long tube. You then insert that tube (the delivery device) into a small incision in the leg, up the femoral artery. The clinician threads is up into the place where it needs to be deployed, and then withdraws the tube, which springs back to its original shape, bridging the blood vessel. This is a less invasive procedure, with far quicker recovery time for the patient.
The problem is, you can’t see what you’re doing. If you’re doing open surgery, it’s right there in front of you, but here you have a device you’re inserting into an incision, and the only control you have is moving it forward and back, and twisting it. To compound matters, you need to position the device very accurately as well.
If you look at the diagram above, you see just above the graft there are two vessels coming off. These are the renal arterys. If you block one of those off the patient loses function of a kidney, so it’s vital that this graft goes where it’s meant to. In slightly more complicated procedures, if the aneruysm was higher up, the graft would have little holes in, or branches, and these need to be positioned exactly into the vessels so you don’t cut off blood flow to them. So, you need some way to see where your device is before deploying it.
These procedures are performed using fluoroscopy (real-time X-ray) guidance. This is a typical fluoroscopy image you’d see during a procedure:
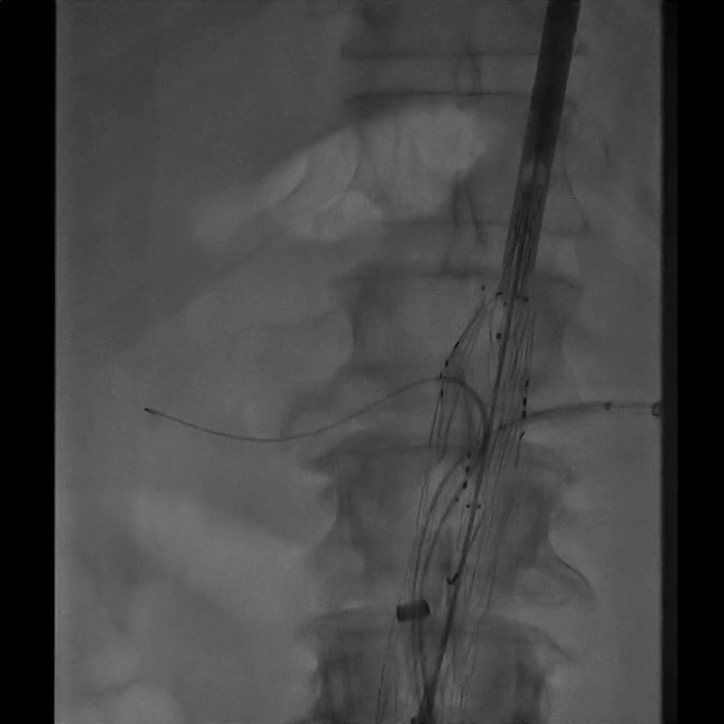
You can see on here, the bone is very clear. This image is part-way through a procedure, so you can see a stent graft, and there are some wires going into the renal arteries. Can you spot what you can’t see on that image? You can’t see the blood vessels. The problem is that blood, blood vessels, and almost everything else in your abdomen, is about the same density as far as X-rays are concerned. You can’t see soft tissue with fluoroscopy.
There is a way around this: you can inject contrast medium, which is an X-ray opaque fluid. This gives a nice, clear picture, showing you exactly where the blood vessels are. The downside is, it’s toxic — too much can also damage your kidneys. Hence, you want to use it as little as possible.
There’s another technique to get around the visibility problem, which is to overlay other information onto the image. This is where Cydar comes in. The other information we use is the preoperative CT scan that has been taken before the procedure. This is what has been used to diagnose the disease in the first place, and to plan the procedure, so this is already existing data. We take that, we segment the bit of anatomy that’s interesting, and we combine it with the fluoroscopy image. This is what the clinician would see for the same image, but using Cydar EV:
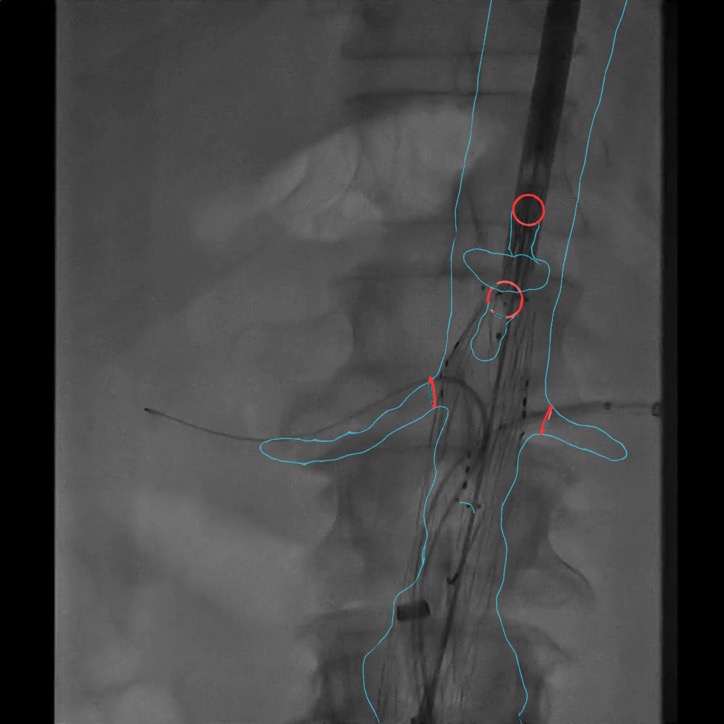
You can now see the blood vessel, and you can confirm that the renal arteries are where you expect them. This allows the procedure to be done in less time, using less X-ray radiation, and injecting less contrast.
(The reduction in X-ray dose is a big benefit to the patient, but also to everyone else in the room. The patient will have one or two of these procedures in their entire life, the clinical team will be doing several every week, so even though they are not directly in the path of the x-rays, the back-scatter is quite an issue.)
There are other systems that do this on the market. They tend to be based on mechanical tracking. It works, but there are two disadvantages compared to how we do it. The mechanical tracking systems track the position (and angle) of the X-ray detector relative to the table. What it doesn’t track is how the patient moves relative to the table, which is a source of inaccuracy, and we’re far more accurate than them. There’s another problem, which is that they’re part of very expensive fixed fluoroscopy sets that are built into the operating theatre. Our system is retro-fitted to could be one of those sets or it could be a far cheaper mobile fluoroscopy set in a regional hospital. We work with essentially any x-ray set.
So, how do we do it? We use cloud based computer vision to find the vertebrae in the image, and match them to the vertebrae in the CT scan. From that, we can work out what the projection of the fluoroscopy image is, do a similar projection on the data from the CT scan, and produce this overlay.
That’s the surgical part over, and that’s the product. So, how does this look in practice, and where do we use TypeScript. I’m going to take you through a few of the parts of the product, and show you where we use TypeScript.
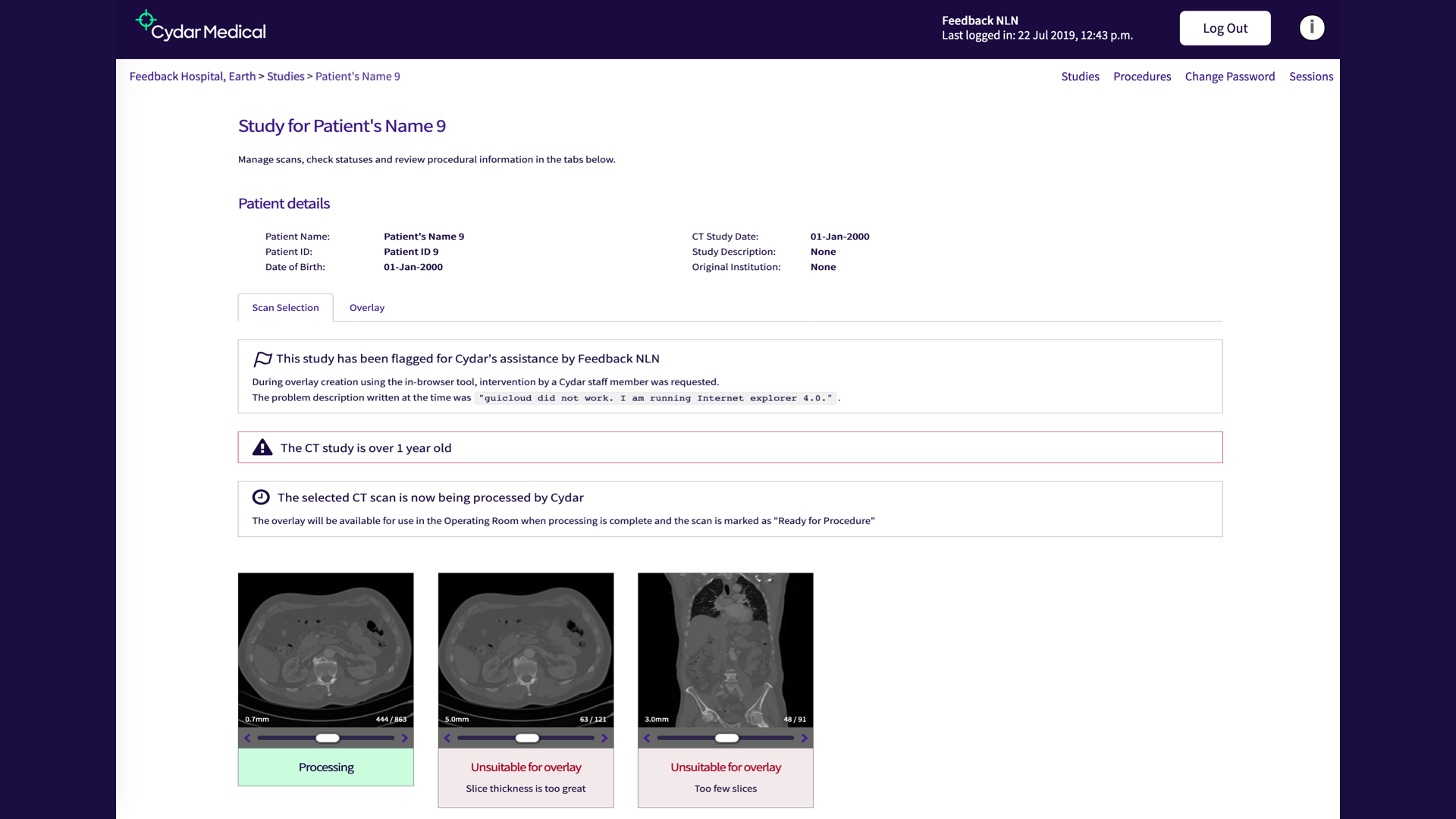
This is what we call the Vault. This is the part of the tool that the clinicians log on to from their desktops in the hospital, they can upload CT scans they want to use with the system, and see how they’re progressing. It’s essentially a fairly conventional database-driven web app, but on the front end we’ve added a fair bit of interactivity. One example is these images at the bottom you can see. You can scrub through them to see if you’re got the right image (you may upload several images for the same patient, not all of which will be suitable).
This is a place where TypeScript is particularly useful, simply as a better way to write JavaScript. This kind of interactivity is the bread-and-butter of client side JavaScript, but writing it in TypeScript is a better experience. The transpilation is quite useful, allowing us to skip an explicit step for browser compatibility, and it makes things easier to organise and keep track of.
The most interactive part of the Vault is the Overlay Creation Tool, which warrants looking at in more detail:
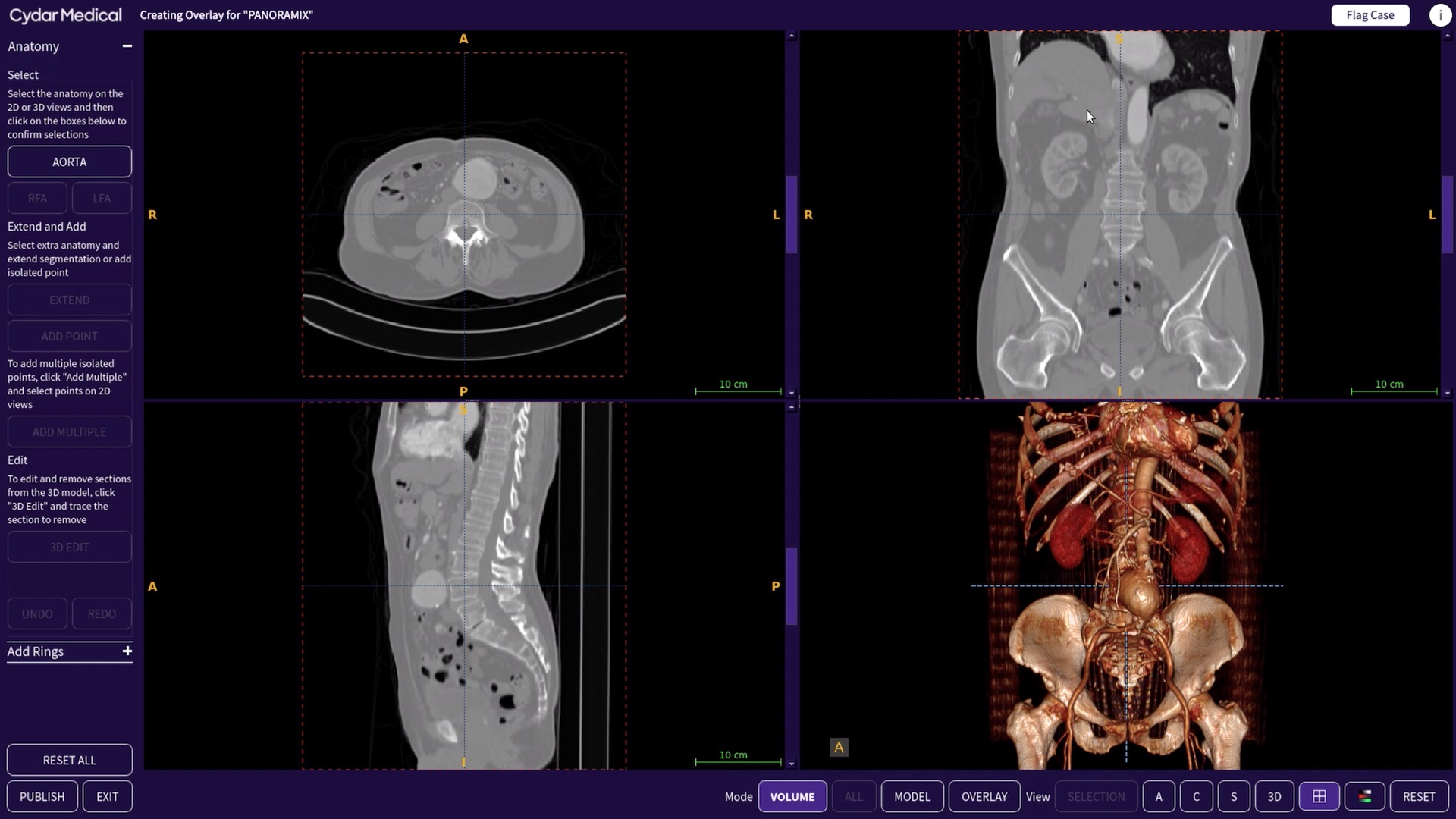
This is a 3D viewer and annotation tool which the clinicians uses to select from the CT scan the anatomy they want to see during the procedure. You see here we’ve picked out the aorta, and you can see the aneurysm. For this kind of application, hospitals would typically have to have dedicated workstation, and you have to go to that to work on your case. We didn’t want that; instead, we wanted clincians to be able to access the tools from their own desktops, anywhere they were.
We considered implementing the Overlay Creation Tool as a pure web app, but the problem with that is you can’t rely on clinicians having a decent computer on their desktop. For example, they are unlikely to have a dedicated GPU. As an alternative, we’ve take a remote desktop approach. The main view is a C++ application running on an AWS instance in the cloud with enough CPU to handle this, and a decent GPU. This means we can give a consistent level of performance. We deliver that via a VNC session in the browser.
The VNC viewer itself is off-the-shelf, but around that we have a fairly complex bit of TypeScript, because it turns out that the trade-off is that you’ve reduced the requirements for local machine performance, but what now matters is network performance. Hence, we have quite a bit of logic in there to track disconnections, and slow down, or events such as the connection pausing and later resuming, and respond correctly. We found it a lot easier to keep track of this in TypeScript, rather than vanilla JavaScript. TypeScript is great for imposing a bit more organisation, and keeping track of what’s going on.
The final bit is, once you’ve done all of this, you get into the operating room:
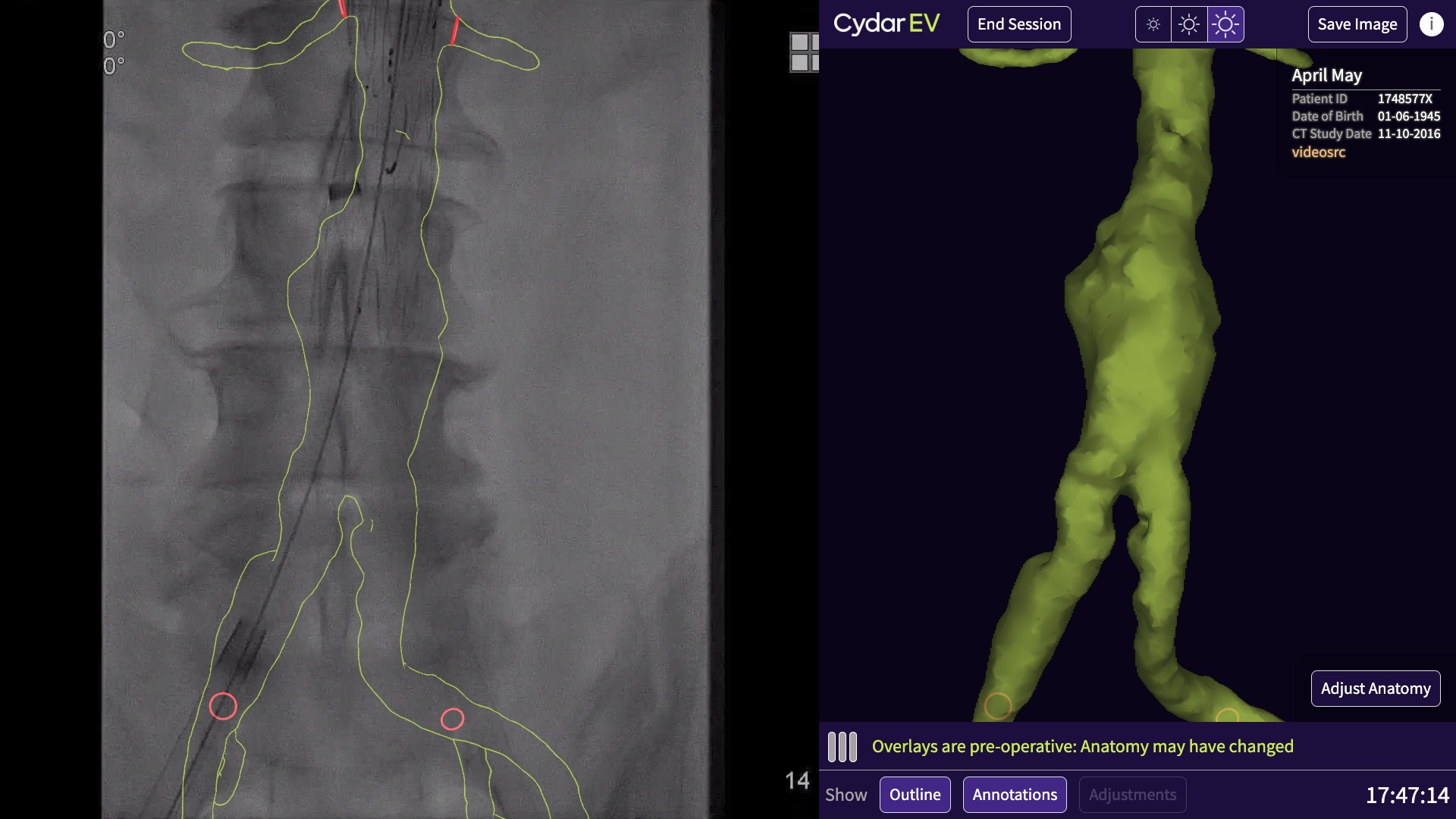
This is running on a touchsceen PC, as shown in the first photo. This is the interface that the clinicians will be looking at while they’re operating. On the left is the fluoroscopy, coming in via a video capture card. We take snapshots of that, send them up to the cloud for processing, and get back and display the results. This isn’t something you’d do with web technology.
But, nevertheless, that’s what we did.
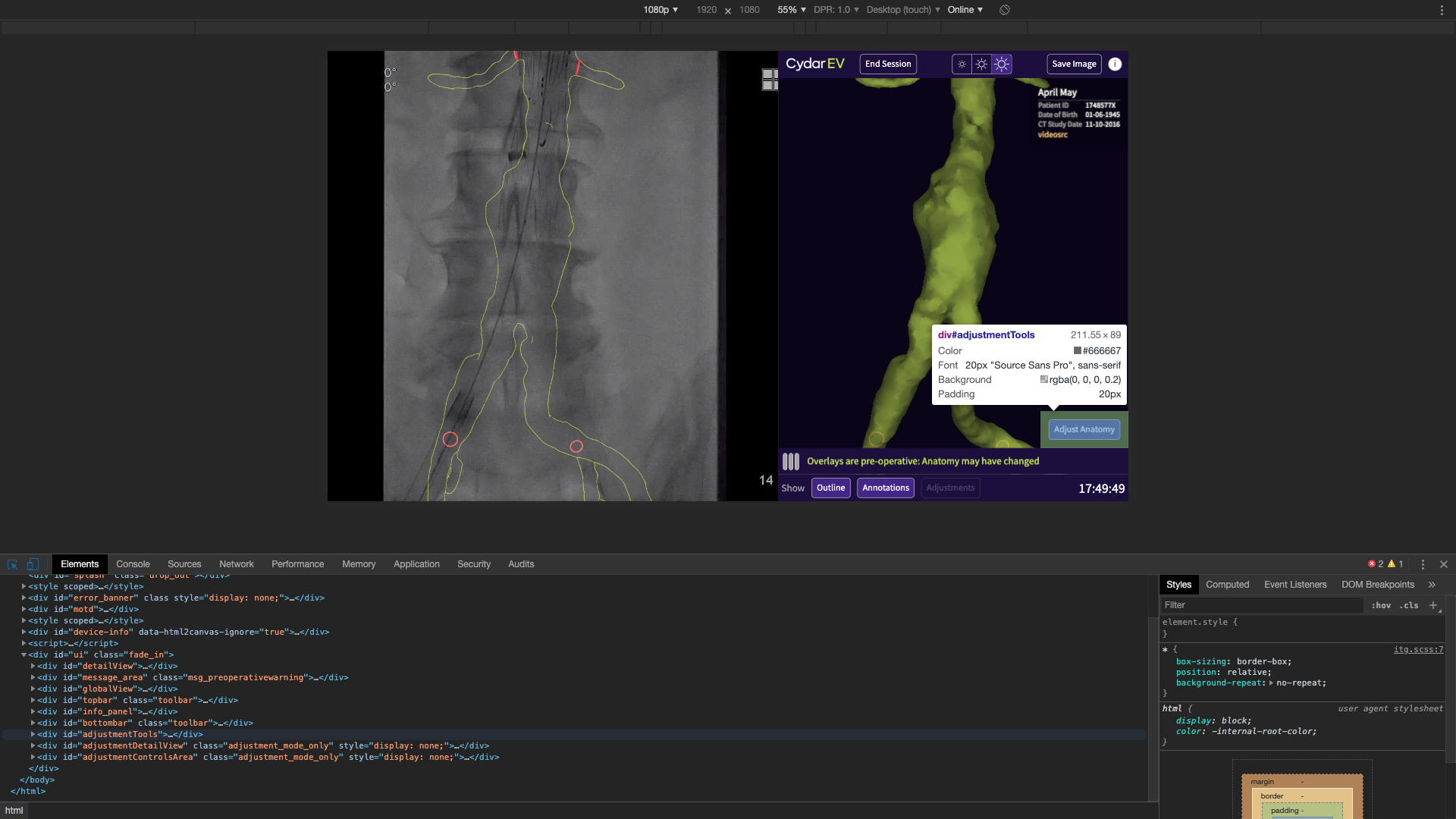
All of this is running on a standard web browser on a that PC in the operating room. This raises a couple of questions: how and why?
You’re all familiar with the web platform, so the how is probably preaching to the choir. The approach we took wouldn’t really have been feasible in, say 2010. However, now, the web platform has got increasingly powerful, and has got a lot of capabilities it didn’t used to have. For example:
- WebRTC allows us to capture the video, without having special native software
- WebGL is used for rendering the overlay itself (the outline is a full 3D render with a special shader)
- WebSockets allow more dynamic communication than request/response
The most important thing is maturity and performance. On the maturity side, the standard web platform has rounded out, with things like Promises and typed arrays. Overall, it has become extensive, mature and stable. It gives you a very strong base to work on. In terms of performance; there’s been a lot of virtuous competition between vendors,and as a result the performance of Javascript is now phenomenal compared to other dynamic languages.
More importantly, why are we taking this somewhat unusual approach to what would normally be an embedded system in a language like C++, using a native toolkit?
To understand this decision, return to this definition:

The key part is “Software medical device”; we didn’t want to be a hardware company. We wanted to be software company, and move at the speed of a software company. You can do hardware as a small company, but especially for medical hardware that’s a very tough proposition. Fortunately, the regulators have been coming round to the idea that you can have a medical device that is purely software.
This is a relative new thing — when we first started the regulatory process for Cydar EV we were working based on guidance from 1997, which meant every time we did a release we had to ask questions like “does this change the sterility of the product”? You can’t really sterilise software, so no.
Things have improved substantially since then, and there is now a special guidance note for purely software devices. For example, under the new FDA guidance, if you answer yes to “is this change to fix a security flaw?” then essentially you don’t need a new approval. If you’re making a change to fix a security issue, they want you to get that out. The regulators are becoming far more aware of software as a medical device. This is why we’re very keen that our medical device is just the software.
This is our setup in the operating room:
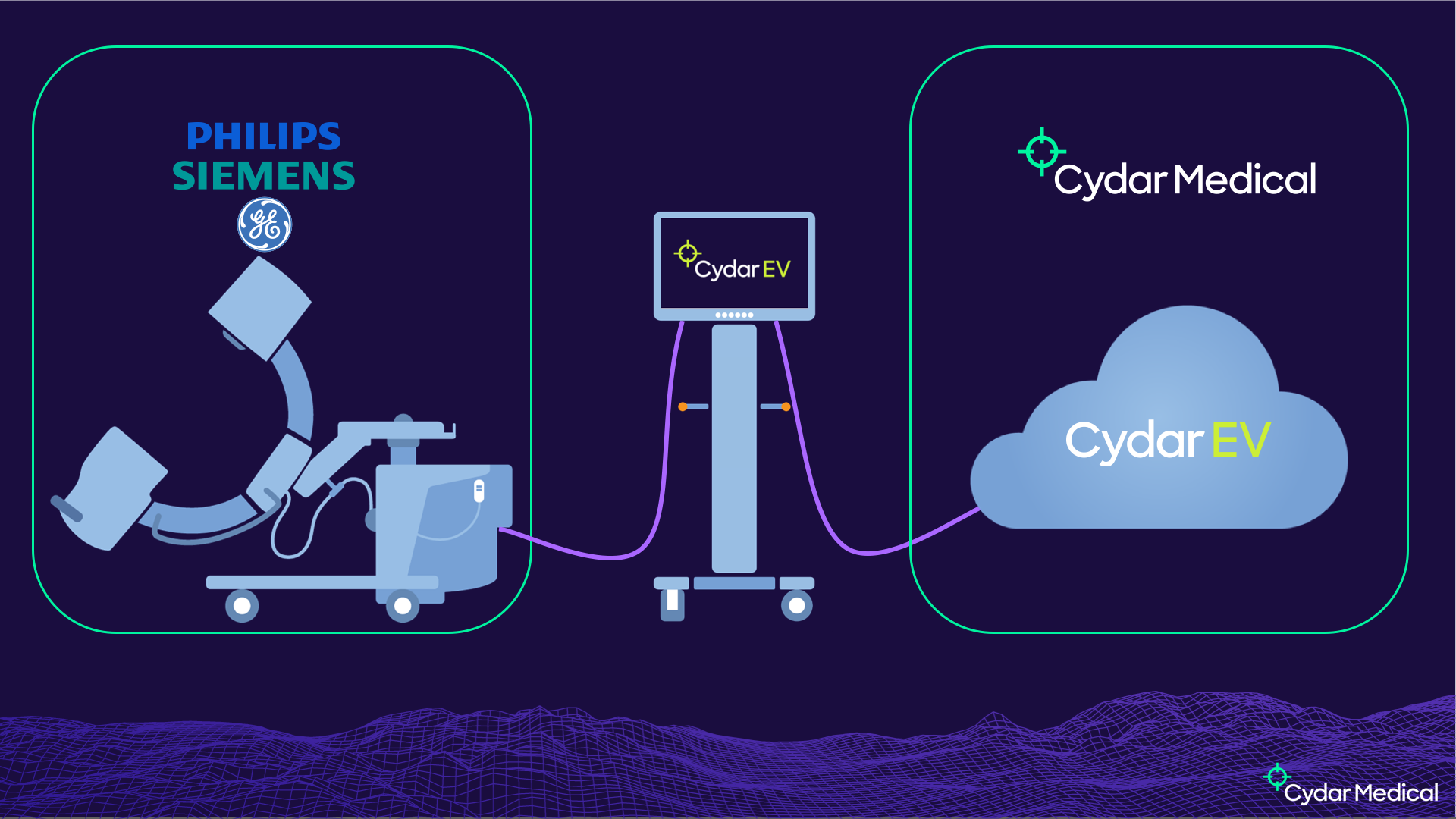
On the left we have an existing medical device, the fluoroscopy set. That is the highest classification of medical device, for obvious reasons — it’s shooting ionising radiation at people. It’s very highly regulated, with a very involved process to get the certification, and if you modify it at all that could invalidate that certification. We don’t want to do anything to modify that device. Fortunately, a standard feature on these devices is a video feed to drive a second monitor. That’s what we put into our capture card, allowing us to get the images from the device without impacting its certification.
On the right hand side, we have Cydar Medical, and Cydar EV. Cydar EV is inherently a cloud system, as we need a very large amount of compute to do the computer vision part. We’ve always put this computing power in the cloud, as we don’t want to be delivering this hardware into hospitals. The Cydar EV software is a medical device in its own right, and that’s what we get the certifications for. This process revolves around having a QMS, with a well established process, a key part of which is taking a risk-based approach.
In the middle, we have what we call the Cydar Appliance. This is a standard PC, running standard software, and is in itself not a medical device. It has to conform to other standards — for example, it has to be cleanable2, but is nevertheless an off-the-shelf device not specific to Cydar. Because of that, all of our software is in the cloud side, and we need a platform where the hardware in the OR is just a dumb terminal essentially. The web is an obvious choice.
That’s why we chose the web platform. How did we get to TypeScript? We started off thinking most of the heavy lifting in C++ and Python on the server side. The client is going to be pretty simple, sending video to the server and displaying the results to the user. The first versions worked like that.
We rapidly realised we were going to have to do a lot more on the client, for two reasons. Firstly, performance. You don’t want that round-trip latency every time. If you can do more locally, you can react to changes quicker.
Secondly, safety. Remember I said a risk-based approach is central to getting medical device certification? The key risk we identified is showing the wrong overlay. If we can have a check that the overlay we’re displaying corresponds to the image that’s on the screen, and we can do that locally, we can enforce that safety constraints without relying on the network. That’s a big win for us for safety.
We developed this functionality in JavaScript, but by the time we’d added the additional computer vision into the client, it was getting very unweildy. So, we had a look around for options to replace JavaScript.

CoffeeScript we dropped quite quickly, as it didn’t really offer us anything over ES6, and even at that time it seemed obvious that the latter was going to have widespread adoption. This left Flow and TypeScript.
This was a far harder choice, as the two systems, certainly in 2016 when we were making this decision, were pretty comparable in terms of power and expressiveness. Two factors swung it. Firstly, I personally prefer the syntax of TypeScript. That’s a nice to have, but isn’t enough on its own. Secondly, tooling. Even then, TypeScript’s tooling was better than Flow’s and it’s just gone from strength to strength since then.
There was another factor, one that was a bit of a gamble in 2016 — popularity. We wanted to be using the one with the broadest community, as opposed to finding ourselves in a niche interest some years down the line. It’s fair to say that that’s paid off — TypeScript is clearly the winner in terms of popularity. It’s also turned out to be an excellent fit for our needs.
The conversion process was straightforward, allowing us to go one file at a time. Once everything was converted we turned strict mode on and kept it on, because that gives the most benefits from static typing. Since then, it’s continued to prove very useful for us.
One of the things I particularly like about TypeScript is the combination of functional and object-oriented types. Many years ago as an undergraduate I learned ML3, and when we started to use TypeScript I dug that knowledge out and ended up writing TypeScript in a very functional style with algebraic types. I really enjoy that, and it works well with the way I think. Other people on the team prefer a more Java or C# style, with classes and interfaces. TypeScript not only allows these two styles to coexist, but allows them to integrate. We could of course have a coding standard that says “you cannot use algebraic types” or “you cannot use classes”, but we’ve found that’s not been necessary, because the two work together. I think that’s one of the big strengths of TypeScript’s type system.
The last thing I want to go over is one place where we’ve found TypeScript particularly valuable. Once we’d converted the code, it was still quite complex and hard to understand what was going on, and reason about what was happening with the system. This was becoming a problem, especially as we want to be confident that we preserve the invariant that we don’t display the wrong overlay compared to the image. I looked around for options as to how to organise the code, and the one we came up with was Redux.

This is one several similar things around that take a functional approach combining an immutable state tree and reducers which take a state and an action and give you a successor state.
What I like about Redux is it’s incredibly simple — you could read the entire source code in an afternoon and you’d be going home early, because it’s a fantastically simple and well-thought-out library. It also fits what we do really well. In particular, I think it’s a very good fit for TypeScript, if you take the time to type your actions.
This is a slightly large union type, defining the acitons that can happen in our In-Theatre GUI (ITG):
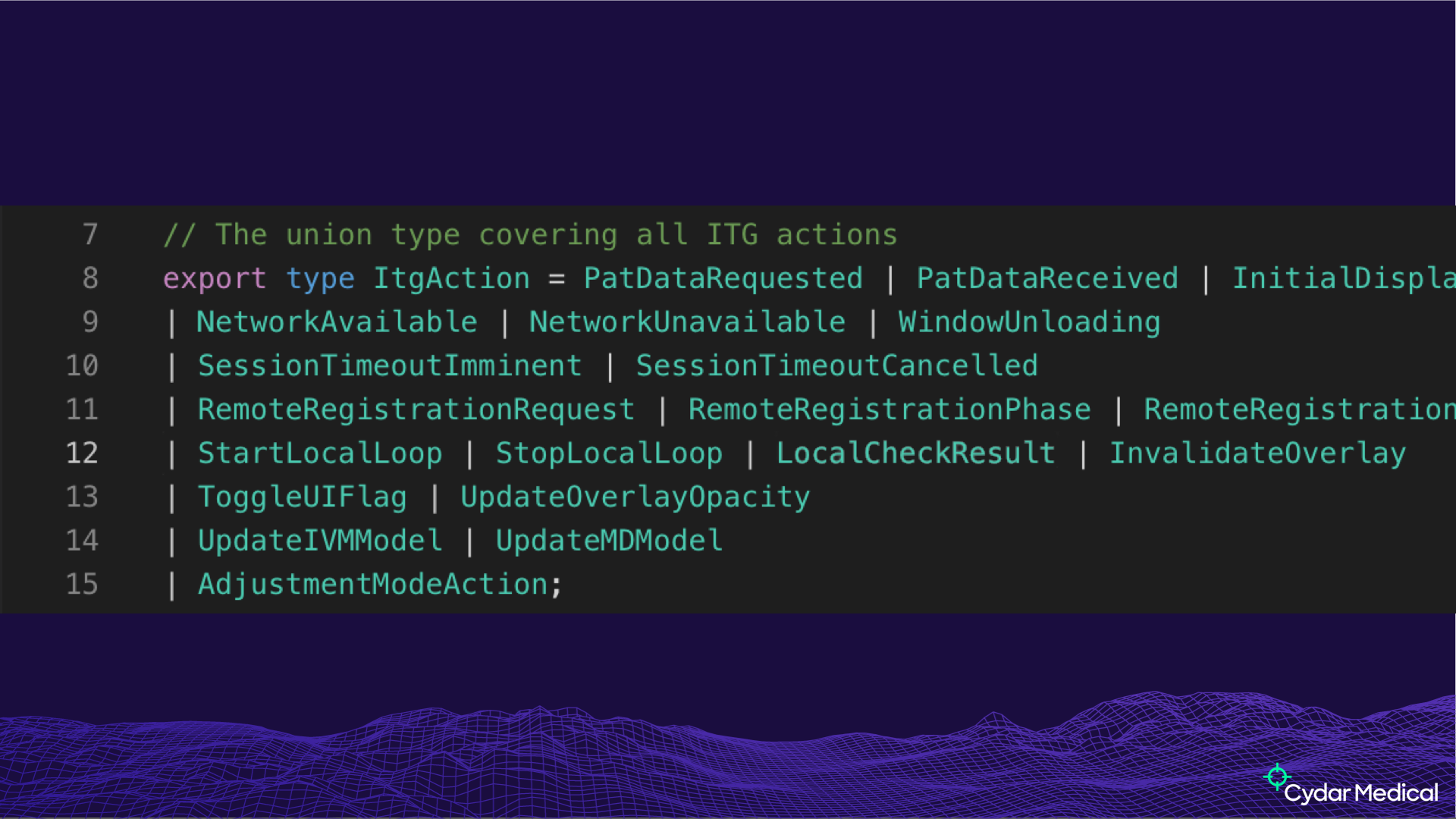
Having a proper type for your actions means that you can be confident that, whenever they’re dispatched, it has the right things in it.
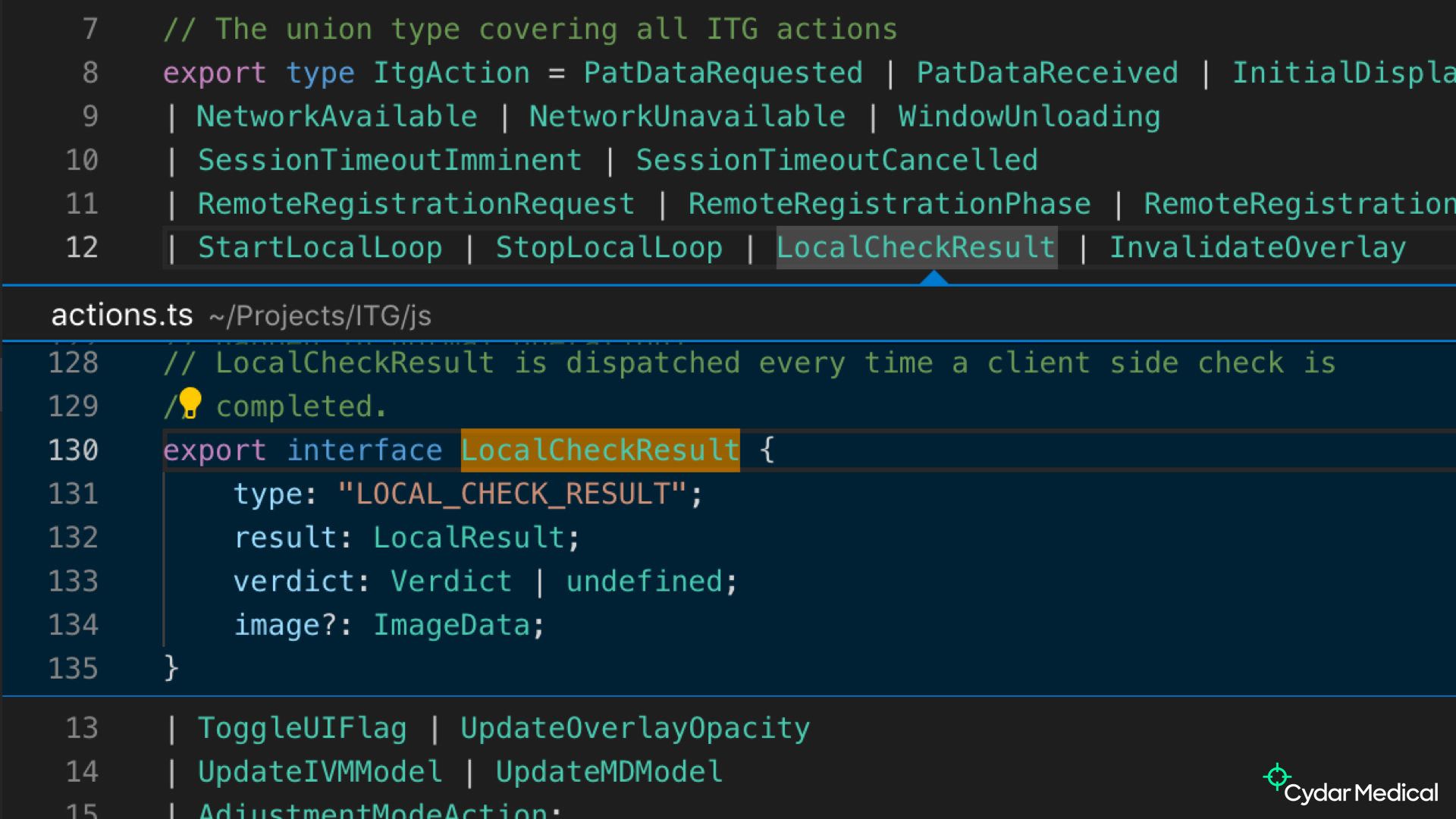
To take a specific example, the LocalCheckResult action above is dispatched when we’ve checked the overlay/image invariant I mentioned. The type ensures we have all the information, and means the reducer doesn’t need to be very defensive (and can thus be a lot simpler).
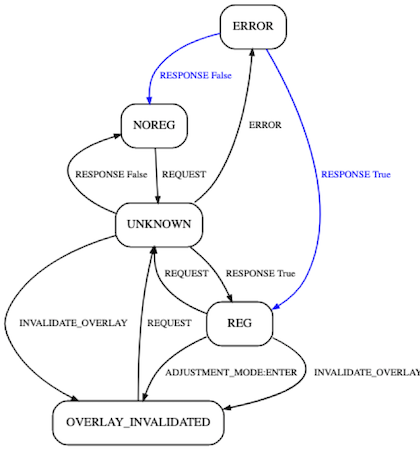
Another thing we can do once we have this set up is log out the states and actions. From that log, we can reduce the data to abstract transition diagrams. Briefly, black arcs are expected transitions that were observed in the test run, blue arcs are transitions that were expected but not observed (comparable to gaps in code coverage), and if there were any red arcs they would represent a transition that occurred but that you weren’t expecting — a CI failure.
This is something that’s revealed actual problems and regressions, where state transitions we didn’t think could happen did. This build directly on the structure provided by strong types and Redux, and makes it a lot easier to reason about what your software is doing.
In conclusion:
- The web platform is powerful enough for almost any application. If there’s an application that would have previously had to be a native application, there are now few technical barriers to implementing it as a web application instead, with the distribution and development advantages that come with it.
- TypeScript lets you develop more complex applications more easily than JavaScript alone, because it gives you the extra support and extra structure to manage these larger codebases.
- Static type checking combines really well with existing JavaScript tools for managing this complexity.
Questions
What do you use for performance monitoring, as you’ll have to check all of this stuff in different browsers, and WebGL is particularly inconsistent across browsers?
We use Selenium for CI testing, but mainly for correctness. In theory you can run the In-Theatre GUI in any reasonably modern browser. Our original plan was to have the hospital provide the PC and browser, but as the question correctly identifies there’s a lot of variation in WebGL (and JavaScript) performance across browser, and hardware, and due to the interaction between the two. What we do for that reason, and for reliability and testing in general, is we have a standardised setup that we provide to go into the operating room, because that’s where the performance is critical. For the desktop use, we check correctness with Selenium, but we accept a degree of variability these as we have limited control over the platform.
Unfortunately, I couldn’t catch the exact question on the recording, but it was something along the lines of “What happens if the network fails during an operation?”
That was the key thing that led us down the path of doing the correctness check locally. If the network fails, the check is still running locally, so if you have an overlay but the image isn’t changing, the overlay will stay there. As soon as the image changes and invalidates the overlay, it will come down immediately, failing safe. Part of our risk assessment is that not showing an overlay isn’t harmful to the patient, because there are many reasons that we wouldn’t be able to show an overlay — the image is poor quality, the necessary anatomy isn’t visible, they’re outside our working range of angles. Showing an incorrect image is potentially harmful, hence we fail safe.
The larger JavaScript ecosystem is pretty chaotic. Have you had any trouble with regulators, using NPM for example? If I was a regulator, I’d worry about that.
Regualators tend to work at a more abstract level — what they worry about is that you’ve got a process. They want to know that you’re looking at it, rather than looking at it themselves. In terms of supply chain, the term for third-party software in the regualtory sphere is SoUP — Software of Unknown Provenance — which means anything that’s been developed outside your QMS. We have to review dependencies and make sure we’re not using anything that has a problem in terms of performance (mainly correctness) or security (more of a concern for the information security side). We keep this manageable by keeping dependencies to a minimum — that was a big factor in the choice of Redux as opposed to a bigger framework such as React. Not only is it small enough to review, but if it disappeared tomorrow we could probably reimplement it (at least the parts we need) in a week. It’s not so much a library as an idea. As an illustration, a little while ago, one of the team posted an implementation of Redux in RxJS on our Slack; it’s literally a single line. The power of Redux isn’t the code, but the idea of structuring your code in those terms.
-
EVAR image © BruceBlaus - Own work, CC BY-SA 4.0 [back]
-
This means it has to be fanless, which has a surprisingly large impact on performance – if you compare a fanless machine with exactly the same hardware but actively cooled, you’d be surprised at what a difference that makes. That’s something we ran into early on. [back]
-
This was before ML stood for Machine Learning. [back]